
Today I’m going to talk about the benefits and implementation of Hypothesis Driven Development (HDD). This topic errs slightly on the side of science, so let’s dust off our lab coats and get into it.
What is Hypothesis Driven Development?
Hypothesis driven development is a movement away from traditional requirements-based development towards hypothesis-based development. I first heard about this methodology whilst checking out Josh Seiden’s presentation from AgileUX NYC. (7)
HDD is based on the scientific method, and is applied by iterating through a series of experiments with your customers as rapidly as possible. Each iteration starts with a clear, testable hypothesis that is then empirically validated through tests run as experiments (1). An experiment is centred on the validated learning loop, or the Build-Measure-Learn loop, which refers to the critical customer feedback loop as pioneered by Eric Ries (4).
With its roots in Lean Startup, Agile and Lean UX, HDD supports the conditions of extreme uncertainty that entrepreneurs face in the Lean Startup environment, and aims to assist in moving towards a revenue generating product as quickly as possible (4). HDD focuses on the idea that requirements can take the creativity out of building a product, and in some instances can actually discourage your team from thinking for themselves(7).
Benefits of HDD
HDD is effective in providing validation – or invalidation – of leap-of-faith assumptions to stakeholders as quickly as possible, ideally before a start-up runs out of money. Experiments also keep everyone working on a product honest, and raise awareness of continuous learning about the product and its inherent environmental fluidity.
One of the most exciting aspects of HDD is the buy-in and engagement from the whole team in the feedback loop. The team is immersed in the full breadth of the product user/market fit, rather than being siloed in the build section of the loop (8). With designers, developers, and testers all being involved in HDD, in the right environment, great outcomes can be fostered in the spirit of inquiry and innovation.
Implementing HDD
I have compiled this illustration the HDD scientific method steps, which I have centred on the validated learning loop (1, 3). During the next section I will talk through each one of these in detail.
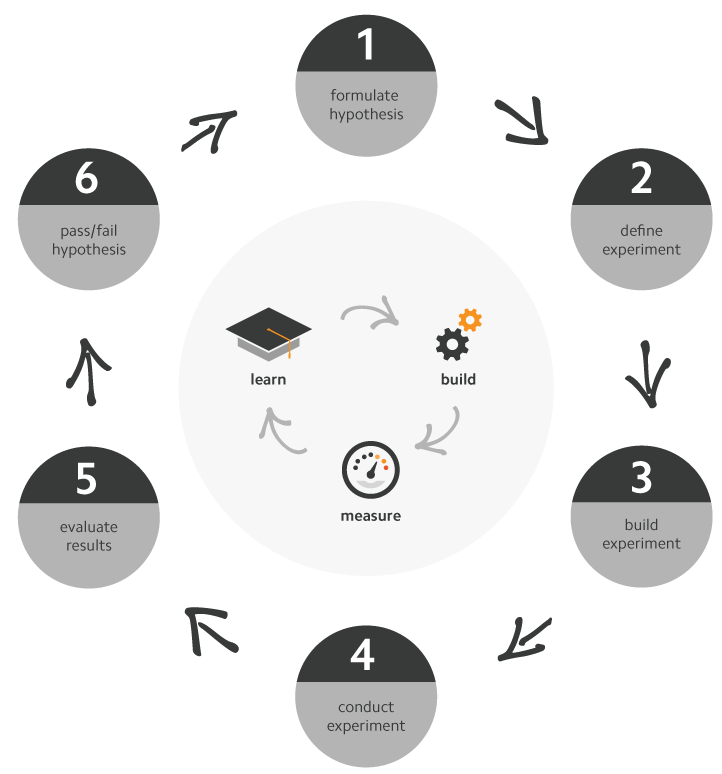

A hypothesis is an educated guess on how something will work based on current information at hand.
A good hypothesis will support experimental design which is vital to validating or invalidating your assumptions(5). In Running Lean, Ash Maurya advises that falsifiable hypotheses are preferred, in order to mitigate the risk whereby entrepreneurs run experiments to simply collect enough evidence to convince them that their theory is correct(4).
A well-crafted hypothesis should capture specific criteria and be testable. It needs to be written as a statement devoid of ambiguity. Documenting leap-of-faith assumptions about your product can be a great place to start, and testing your riskiest assumptions first is also a great way to prioritise your experiments.
Ash Maurya recommends the following format for constructing Falsifiable Hypothesis: Specific Repeatable Action will drive Expected Measurable Outcome(4).
Throughout the following implementation section, I will refer to an example based on an experiment conducted on a real-life project. This particular project focused on offering free online courses, with each course running for a four week period (referred to as a cohort). Once a cohort ended, there was a one week break before the next cohort (cohort 2) commenced. Enrolments were opened two weeks before cohort 2 started, and closed the day before it finished.
Social learning was core to this product’s success, with forum collaboration and discussion designed to enhance a student’s learning experience. The Product Owner was keen to explore how completion levels could be improved if students studied with their friends. Student feedback was gathered, and it was discovered that closing enrolments as soon as someone started a cohort was limiting the ability for students to share their interest in the course with their friends once they had started studying.
What we wanted to find out was: if enrolments were left open after a cohort started, would this have any effect on student completion (pass) rates for any given cohort. Our assumptions were based on the following:
1. We assumed students would want to study with their friends, who may have already commenced a cohort.
2. We assumed students who studied with people that they knew and/or engaged in social learning would have a better chance of passing.
The final hypothesis was determined as:
Extending the enrolment period by one week on Basic Math will drive the cohort pass rate 2% higher than last cohort.

The experiment should be the absolute bare minimum to test the hypothesis, in the spirit of reducing inventory, risk and waste. Experiments should build on one another and be strung together, rather than being monolithic(6). All experiments should be time-boxed, no matter how tempting it may be to run them for “just a bit longer”.
In my example, we worked on the premise that one course from our catalogue would be enough for our experiment. We identified a course with a significant sample size – Basic Math – for our experiment target, and identified that we needed the experiment deployed just before enrolments opened. We needed to build and deploy the change for Basic Math only, and then ensure we had the capability to accurately measure results. The experiment was inherently time-boxed and only ran for the duration of the cohort.

Succinct, sensible software development is instrumental in the HDD process, as you may wish to implement the change across the board if the experiment succeeds, build on it, or easily roll back if it fails. Therefore it is imperative that code is written in an extensible fashion, and test-driven development very important. Speed is also critical, meaning that if you need to refactor significant lines of code to deploy the experiment, then the experiment and/or implementation may need some additional thought.
In my example, extending enrolments for Basic Math was able to be completed well in advance of the cohort enrolments opening. The ability to measure completion rates in courses by cohort as time progressed was already built manually, and whilst this wasn’t the most convenient way to measure, it was just enough to run our experiment. We collected completion rates for the last cohort of Basic Math for our comparisons.

Speed is critical in proving or disproving your hypothesis; ideally, you want to have it tested as soon as possible(4). I should add here that there many more advanced ways in which to measure your success other than our manual method, however speed and whatever method of measuring makes sense for your experiment will be a decision made on a case by case basis.
In my example, we collected daily data on completion rates for the duration of the Basic Math cohort, which was added to Excel and graphed by day.
It’s also fairly important to establish a regular communication format throughout your experiment and to have a way of visualising them. Ash Maurya’s Lean Dashboard is pretty cool(10).
It’s also possible to track the progress of your experiments on a physical wall, as long as you are not constrained by teams working remotely.

Once the experiment is complete, it’s time to review the qualitative and quantitative data collected and to summarise the validated learning. In my example, we took our graph of completions from the tested cohort of Basic Math, and compared the total to the gross completion rate from the previous cohort.
In our case, we had reached the following result:
Extending the enrolment period by one week on Basic Math had driven the cohort pass rate 4.65% higher than last cohort
The approach taken in my example is called the ‘naive approach’, as we have simply compared the gross enrolments to the last cohort. Since the systems we run our experiments on are subject to a level of complexity and randomness that is not possible to completely control, scientists advise that you use Statistical Hypothesis Testing to ensure that your measurements are statistically significant rather than being random noise. [10]
Statistical Hypothesis Testing requires you to “fix a significance level, formulate a hypothesis called the null hypothesis, and then compute if the null hypothesis is rejected or not.” [10]

The final step is to validate or invalidate your hypothesis via the experiment results. Failed hypotheses often contain the best insights, and do not necessarily mean that you need to pivot. Finding a business model that works generally requires a lot of failed experiments first – and failed experiments are the best to learn from(4, 5). Whys root-cause analysis on failed experiments is where you will find most of your breakthrough insights (6).
The end goal isn’t necessarily to prove that the hypothesis was correct, but rather to test your theories and grow a successful business. Whether the hypothesis passed or failed, you should still document the results, update the wall and move onto the next experiment.

By discussing HDD and its implementation, I hope I’ve been able to share with you my passion for this methodology and its ability to empower the delivery team by increasing their engagement with the overall product strategy and form some trailblazing ideas in the process! I’d love to hear about the wins and learnings of others in the HDD space; please leave your comments in the section below.
Further reading:
- Ries, E. 2011, The Lean Startup, Crown Publishing Group, USA.
- Maurya, A. 2010, How to Identify a Lean Startup, viewed 2 May 2014.
- O-Reilly, B. 2013, How to Implement Hypothesis-Driven Development, viewed 1 May 2014.
- Maurya, A. 2012, Running Lean, Second Edition, O’Reilly Media Inc., CA, USA.
- Hypothesis, Wikipedia, viewed 2 May 2014.
- Spark59, Running and Tracking Experiments, viewed 2 May 2014.
- Seiden, J. 2012, Replacing Requirements with Hypotheses, NYC, viewed 14 April 2014. Replacing Requirements Video.
- Lean UX Meetup, Las Vegas 2013, Writing kick-ass hypotheses, Las Vegas, viewed 2 May 2014.
- Maurya, A. 2012, How We Use Lean Stack for Innovation Accounting, viewed 2 May 2014.
- De Vega, M. 2013, Interpreting Measurement Data, viewed 2 May 2014.
